
OK, everybody get on your beanie hat with the spinny propeller – it’s uber dork time.
As I continue work on my PowerPoint opus magnum on magnetic declination I’m becoming reacquainted with issues, concepts and developments I never paid much attention to in my years of work in the topographic field.
One of these developments is the US National Grid System. (Hey, I warned you this was going to be a dorky post.)
Huh? The US National Grid System?
While the US Geological Survey (USGS) has done an outstanding job of mapping the US at large scales (1:24,000 and 1:100,000) there has never been an ‘official’ map grid system selected for use on US topographic maps. For decades USGS maps have sported both Universal Transverse Mercator and Latitude/Longitude grid tics, in sort of a ‘we can’t make up our minds, so we’ll give you everything’ approach. Problem is that the UTM grid system, while accurate, is clumsy and somewhat difficult for the average hiker, Boy Scout or search and rescue team member to use. Soooo many numbers, and little numbers and big numbers, and some numbers that are repeated, and numbers going north have more digits than the numbers going east. Plus, you have to draw your own lines to connect the tic marks and create your own grid. It’s all so confusing. And cumbersome. And unnecessary.
Waaaaay back in the late 1940s the US Army got it figured out, and created the Military Grid Reference System (MGRS). MGRS was (and still is) a map grid system based on the UTM coordinate system, but it is greatly simplified so that a soldier can locate himself with an alphanumeric designator that uniquely describes his position anywhere in the world. The Army extended this standardized coordinate system around the globe (including the US) and over the years has produced hundreds of millions of maps using the MGRS coordinate system. Along the way the Army simplified and standardized map reading techniques using MGRS in conjunction with coordinate scales and compasses, published one of the premiere texts on map reading and land navigation (FM 21-26) and proceeded to teach millions of Soldiers, Marines and the occasional Sailor and Airman the finer points of map and compass work.
Unfortunately the USGS never followed the Army’s example. With only minor exceptions, USGS 1:24,000 scale topographic maps remained grid-less. Users were left to draw their own grids on their maps and figure out the maddening complexity of the UTM coordinate system.
Aaah, but the times, they are a-changing! Recognizing the growing need for a comprehensive national map grid system and spurred, I’m sure, by the post 9/11 drive for standardization and interoperability in national, regional and local disaster response efforts, the USGS has adopted a national map grid system. After much study, conferencing, research, investigation and consideration the USGS took the bold step of…. simply adopting the US Army’s Military Grid Reference System. Now, this is not a bad decision. In fact, it’s a great decision, but geezus guys, you could have done this like, oh, the middle of the last century!
But let’s give credit where credit is due. Once the USGS decided to adopt the US National Grid System they jumped on it like a duck on a junebug. All maps produced under the new US Topo series will incorporate the US National Grid System, will have the full grid overprinted on the map, and legend information will include the full USNG grid identification diagram.
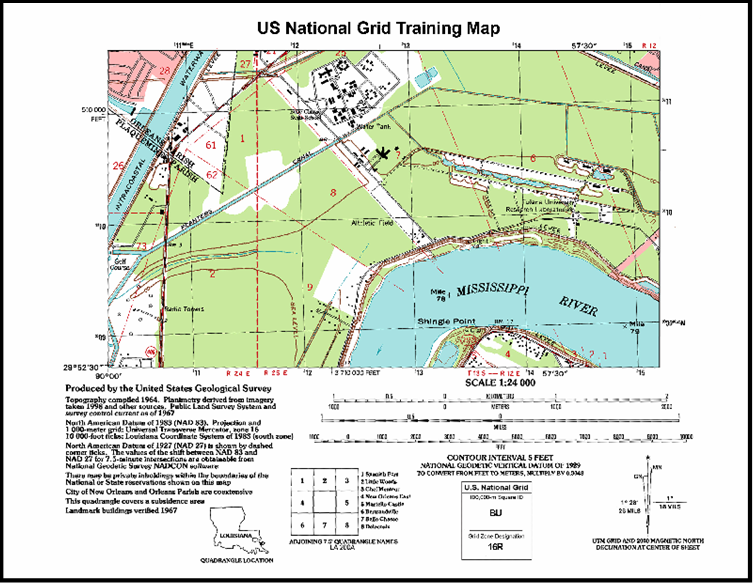
The great news is that if you remember your old Army map reading instructions, the US National Grid System works exactly like the Military Grid Reference System – heck, it is the Military Grid Reference System*, just implemented at a different scale (1:24,000 vs. 1:50,000). All the old rules are the same – remember to include the Grid Zone Designation and the 100,000 meter Square ID. And don’t forget to read right and up!
The best way to learn to use the new US National Grid System is to download the Army’s classic field manual on map reading and land navigation, FM 21-26. This FM is approved for public release so feel free to download it and study it. While the mechanics of map location are the same between grid systems, just remember that the scales are different. You can also download and print a US National Grid practice map (shown above) and a 1:24,000 coordinate scale from the Federal Geographic Data Committee US National Grid website.
So, your homework for this week is to download FM 21-26, the practice map and a coordinate scale and practice, practice, practice. There’ll be an exam next week!
Brian
*OK, MGRS and the USNG are not exactly the same, but close enough that the difference doesn’t matter. MGRS is built on the WGS 84 datum and the USNG is built on the NAD 83 datum. The ground difference between these datums are roughly 1 meter. For land navigation purposes this difference doesn’t really matter. Hey, once again, I told you this was going to be a dorky post!

Priority US National Grid links for more information regarding implementation;
a) http://dhost.info/usngweb/
b) http://mississippi.deltastate.edu/
c) http://mississippi.deltastate.edu/data/USNG_Atlases/
d) http://www.floridadisaster.org/gis/usng/
e) http://www.mngeo.state.mn.us/committee/emprep/download/USNG/index.html
f) http://www.floridadisasterengineers.org/library.html
g) http://www.usfa.dhs.gov/downloads/pdf/git_usng_intro.pdf
h) http://www.usfa.dhs.gov/downloads/pdf/campus_map_usng.pdf
i) http://www.ffca.org/files/public/FFCA_SERP2010_FINAL4.pdf
Also, USNG training includes ¨right, then up¨; so Easting & Northing would be slightly more appropriate. 🙂
Regards,
Websites of priority interest ref: USNG
a) http://mississippi.deltastate.edu/
b) http://www.mngeo.state.mn.us/committee/emprep/download/USNG/index.html
c) http://www.floridadisaster.org/gis/usng/
d) http://www.floridadisasterengineers.org/library.html
e) http://dhost.info/usngweb/
f) http://www.usfa.dhs.gov/downloads/pdf/git_usng_intro.pdf
h) http://www.usfa.dhs.gov/downloads/pdf/campus_map_usng.pdf
Also, in training for USNG, we state, ¨right, then up¨. Therefore, Easting & Northing, would be more appropriate. 🙂
Finally, maps for areas of (19) states are here: http://mississippi.deltastate.edu/data/USNG_Atlases/
Regards,
email to: usng08@gmail.com
Welcome aboard.
http://statter911.com/category/u-s-national-grid/
More to follow….